「語彙プロファイラー」で学習すべき英単語を見つける方法:Compleat Lexical Tutorの使い方
英単語を学ぶ上では、重要な単語を、様々な活動でバランスよく学習することが欠かせません。それでは、どのようにすれば「重要な単語」を特定できるのでしょうか?
ある単語が重要であるかどうかを判断する際に役立つ基準の1つとして、その単語の出現頻 (frequency) 挙げられます。わかりやすくいえば、会話や書籍で頻繁に使用される単語は、たまにしか出てこないマイナーな単語よりも優先して学ぶに値する、ということです。
単語の出現頻度に関して重要なことは、ごく少数の単語があらゆるテキストの大部分を占め、それ以外の大多数の単語は、ほとんどまれにしか出現しないということです。これは「Zipfの法則」と呼ばれます(Zipfの法則に関しては、こちらのYouTubeビデオの解説がわかりやすく、お勧めです)。
重要な英単語とそうでない英単語
英語では頻度に応じて、単語を以下の3つのグループに分類することが一般的で (Nation, 2013)。
| 単語グループ |
頻度レベル |
語数 |
カバー率 |
| (1) 高頻度語(high-frequency words) |
1000語~3000語 |
3000語 |
約94~95% |
| (2) 中頻度語(mid-frequency words) |
4000語~9000語 |
6000語 |
約3~4% |
| (3) 低頻度語(low-frequency words) |
10000語以上 |
多数 |
約2% |
上表の「カバー率」とは、ある単語がテキスト全体の何%を占めているか(カバーしているか)を指します。例えば、英語で最も頻繁に使われる単語は定冠詞the ですが、the だけであらゆるテキストの約7%を占めると言われています(つまり、英語で文章を読むと、100語に7回の割合でtheが出てくる、ということです)。この場合、the のカバー率は7%となります。ちなみに、一般的な英語の書籍では、1ページに含まれる単語は約300語程度だと言われています。the のカバー率が7%だと考えると、1ページ中に21回もtheという単語が登場する計算になります。
英単語の3つのグループについて見てみましょう。1つ目のグループである高頻度語は、英語で最も頻度が高い3000語から構成されます。このグループに属する3000語だけで、一般的な英文テキストの約94~95%をカバーします。1語を学ぶごとにカバー率を大きく増やすことができるので、非常にコスト・パフォーマンス(費用対効果)が高い単語と言えます。英語を学習する上では、まずこの高頻度語をどのような手段(単語カードや単語帳など)を使ってでも良いので覚えましょう。
2つ目のグループである中頻度語は6000語から構成され、一般的な英文テキストの約3~4%を占めます。高頻度語と比べると1語あたりのカバー率はだいぶ下がりますが、会話・映画・小説・新聞を理解するには、6000~9000語程度を知っている必要があるという研究があります(Nation, 2006)。英語の上級者になるためには、高頻度語3000に加えて、中頻度語6000もぜひおさえておきたいところです。
3つ目のグループは、低頻度語と呼ばれます。高頻度語・中頻度語以外の単語は、すべて低頻度語に分類されます。低頻度語は数多くありますが、一般的な英文テキストにおけるカバー率はすべて合わせても2%程度にしかなりません。そのため、学習すべき優先順位は低くなります。高頻度語と中頻度語を完全にマスターしたという学習者でない限り、低頻度語をあえて学習する必要はないでしょう。
英単語を学ぶ上で重要なことは、ごく少数の単語(高頻度語)があらゆるテキストの大部分を占め、それ以外の大多数の単語(中頻度語や低頻度語)は、ほとんどまれにしか出現しないということです。例えるなら、英単語はごく少数の働き者と、その他大勢の怠け者から成り立っている、ということです。
注)「最も頻度が高い単語3000語で、あらゆるテキストの約94~95%をカバーする」といった場合の「1語」とは、「ワードファミリー」(word families) 呼ばれるものです。ワードファミリーでは、ある英単語の活用形や派生形も含めて、「1語」と数えます。例えば、includeのワードファミリーには、その活用形であるincludes, included, includingや、派生形であるinclusive, inclusionが含まれます。
語彙プロファイラーで英単語の頻度を調べる
せっかく英単語を学習するのであれば、めったに出会わない怠け者の単語ではなく、頻繁に出会う働き者の単語を学ぶようにしたいものです。働き者の単語と怠け者の単語を見分けるためには、「語彙プロファイラー」というツールが有益です。
語彙プロファイラーには様々なものがありますが、本稿ではVocabProfilerをご紹介します。VocabProfilerはケベック大学モントリオール校のTom Cobb教授が開発したもので、https://www.lextutor.ca/vp/comp/から無料で使用できます。
VocabProfilerの使い方
VocabProfilerで語彙レベルを調べるためには、画面中央のボックスに、分析したい英文テキストを貼り付けます。ここでは、例としてNew York Timesの“Republicans Grind Impeachment Inquiry to Halt as Evidence Mounts Against Trump”という記事 (2019年10月23日) を貼り付けます。
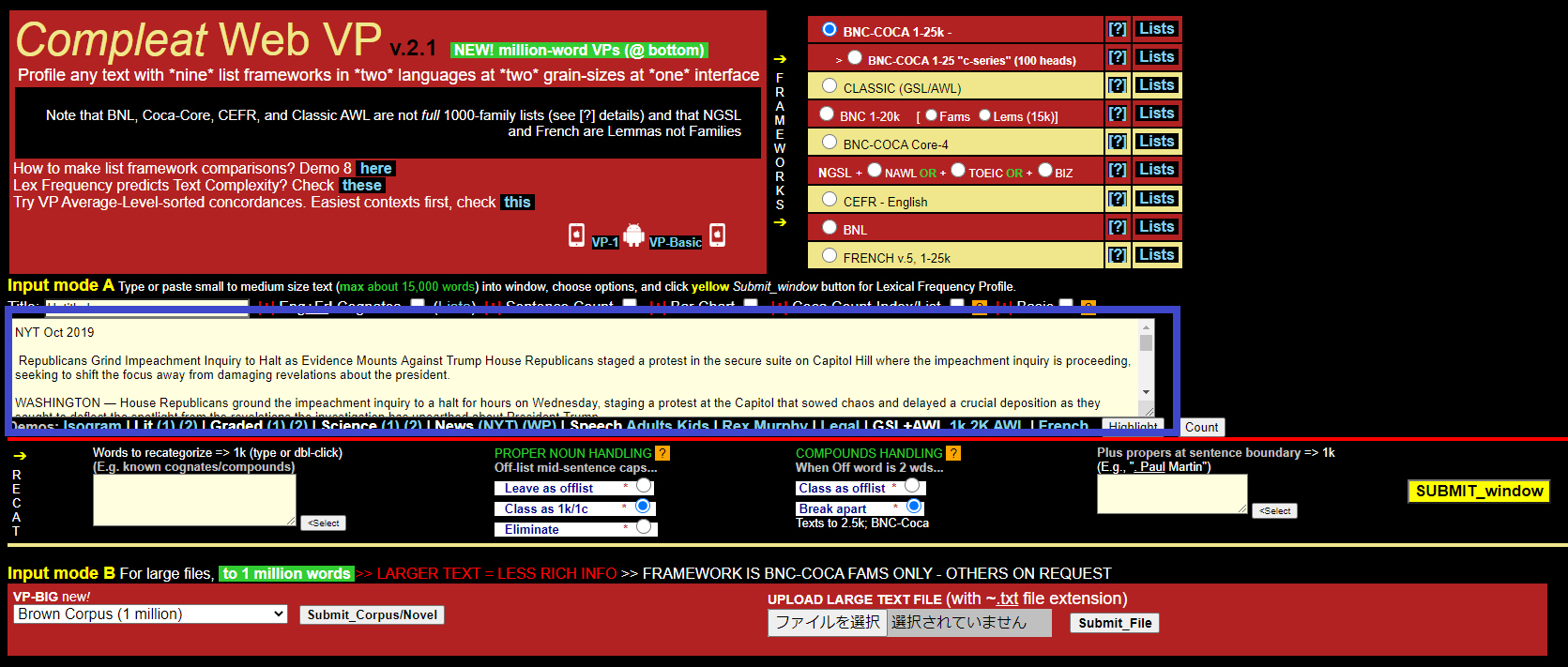
*画面中央のボックス(上の写真で青く囲った部分です)に、分析したい英語の文章を貼り付けます。
テキストを貼り付けた後は、画面右上にある“FRAMEWORKS”というボックスの中から、分析に使用する語彙リストを選択します。通常は一番上にある「BNC-COCA 1-25k」を選択することをお勧めします。
その後、画面右下にある黄色い [SUBMIT_window] ボタンをクリックします。すると、以下のように分析結果が表示されます。
 分析結果の上の方にある表をご覧ください。この表の「Tokens (%)」は、それぞれの頻度レベルの単語が文中の何%を占めて(=カバーして)いるかを表します。例えば、「K-1」という行の「Tokens (%)」には「78.7%」とあります。これは、1000語レベルの単語(K-1)がこの文章全体の78.7%を占めているという意味です(1kや2kの“k”とはkilo、すなわち1000という意味です)。つまり、この英文記事中で用いられている単語の約8割は、英語で最も頻度が高い1000語が占めている、ということです。
分析結果の上の方にある表をご覧ください。この表の「Tokens (%)」は、それぞれの頻度レベルの単語が文中の何%を占めて(=カバーして)いるかを表します。例えば、「K-1」という行の「Tokens (%)」には「78.7%」とあります。これは、1000語レベルの単語(K-1)がこの文章全体の78.7%を占めているという意味です(1kや2kの“k”とはkilo、すなわち1000という意味です)。つまり、この英文記事中で用いられている単語の約8割は、英語で最も頻度が高い1000語が占めている、ということです。
次に、「K-2」という行の「Tokens (%)」には「7.0」とあります。これは、2000語レベルの単語(K-2)がこの文章全体の7.0%を占めているという意味です。
次に、同じ表の一番右にある「Cumul. token(%)」の行をご覧ください。この列は、「累積カバー率」(cumulative coverage) 表します。例えば、「K-1」という行の「Cumul. token (%)」には「78.7%」とあります。これは、1000語レベルまでの単語(K-1)がこの文章全体の78.7%を占めているという意味です。
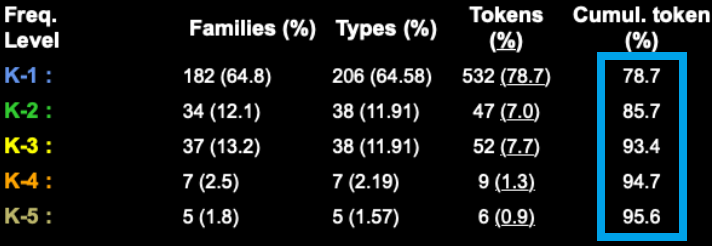
その下の「K-2」という行の「Cumul. token (%)」には「85.7%」とあります。これは、2000 (k-2) ベルまでの全ての単語、すなわち、1000語レベルと2000レベルの単語を合計すると、英文中の85.7% (= 78.7% + 7.0%) 単語をカバーできる、という意味です。つまり、この英文記事で用いられている単語の85.7%は、英語で最も頻度が高い2000語から構成されている、ということです。
この表はさらに、「Coverage 95」と「Coverage 98」という2つの線で区切られています。
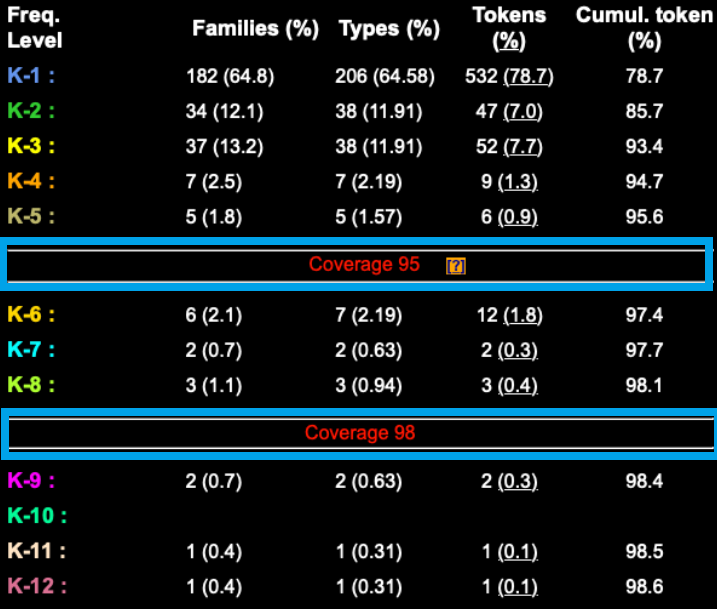
「Coverage 95」とは、「英文中で用いられている95%の単語をカバーするのに必要な語彙レベル」を表します。この表では、5000語レベル(k-5)の下に「Coverage 95」という区切りが入っています。つまり、この英文記事で用いられている単語の95%をカバーする上では、少なくとも5000語を知っている必要がある、ということを意味します。念のため5000語レベル(k-5)の「Cumul. token (%)」を見てみると「95.6%」となっており、英語で最も頻度が高い5000語を知っていれば、この英文記事の95%以上をカバーできる、ということが確認できました。
ちなみに、標準的なテキストであれば、3000語レベルまでの単語(高頻度語)で94〜95%の単語はカバーできることが知られています。5000語を知らないと95%のカバー率に達しないという点で、このNew York Timesの記事は比較的難易度が高いと言えます。
「Coverage 98」とは、「英文中で用いられている98%の単語をカバーするのに必要な語彙レベル」を表します。この表では、8000語レベル(k-8)の下に「Coverage 98」という区切りが入っています。つまり、この英文記事で用いられている98%の単語をカバーする上では、少なくとも8000語を知っている必要がある、ということを意味します。8000語レベル(k-8)の「Cumul. token (%)」を見てみると「98.1%」となっており、英語で最も頻度が高い8000語を知っていれば、この英文記事の98%以上をカバーできる、ということが確認できました。
95%・98%のカバー率がなぜ重要なのか?
ところで、なぜ英文中で用いられている95%(あるいは98%)の単語をカバーするのに必要な語彙レベルを知る必要があるのでしょうか? それは、「学習者が辞書などを使わずに自力で文章を理解するためには、文中の95〜98%以上の単語を知っている必要がある」という研究結果があるからです。すなわち、100語から構成されるテキストを自力で読んで理解するためには、その内の95〜98語以上が既知であることが望ましいということです。
VocabProfilerによる分析結果をふまえると、今回分析したNew York Timesの記事を自力で理解するためには、5000〜8000語レベルの語彙力が必要であると推定されます。
なお、どのくらいの英単語を知っているかを調べる際には、以下のwebサイトに掲載されているVocab Levels Test, Vocab Size Test, Updated Vocab Levels Test等のテストが活用できます。
https://www.lextutor.ca/tests/
難しい単語を特定する
分析結果の画面で一番下までスクロールすると、「Families List」と書かれたセクションがあります。ここでは、英文テキストに登場した単語が頻度レベルごとに提示されています。例えば、このセクションで1kに分類されている単語は、「最も頻度が高い単語1000」を示します。下の画面では、青字で表示されている単語がこれに該当します (a, about, across, Adam, afterなど)。
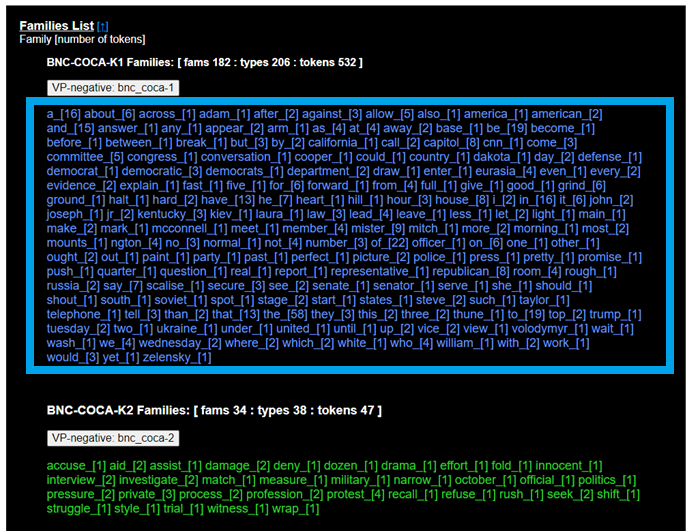
次に、2kに分類されている単語は、2000語レベルの単語を示します。上の画面では、緑色で表示されている単語がこれに該当します (accuse, aid, assist, damage, denyなど)。
各単語の後の[ ]は、その単語がテキスト中に登場した回数を指します。例えば、a_[16]は、“a”という単語が全部で16回登場したことを表します。
ここで、冒頭に示した英単語の分類に戻りましょう。英語では頻度に応じて、単語を「高頻度語」(1000語〜3000語レベル)、「中頻度語」(4000語〜9000語レベル)、「低頻度語」(10000語レベル)という3つのグループに分類することが一般的でした。
今回分析で用いたNew York Timesの記事では、中頻度語(4000語~9000語レベル)に該当するのは以下の単語です。
| 語彙レベル |
英単語 |
| 4000語レベル |
chaos, ms, obstacle, senator, sergeant, suite, testimony |
| 5000語レベル |
chant, enlist, smear, sow, withhold |
| 6000語レベル |
deflect, deposition, hush, impeach, juror, notwithstanding |
| 7000語レベル |
defiance, transparency |
| 8000語レベル |
onslaught, quid, unearth |
| 9000語レベル |
incriminate, subpoena |
また、低頻度語(10000語レベル以上)に該当するのは以下の単語です。
| 語彙レベル |
英単語 |
| 10000語レベル |
該当なし |
| 11000語レベル |
quo |
| 12000語レベル |
standoff |
| 13000〜17000語レベル |
該当なし |
| 18000語レベル |
ultraconservative |
VocabProfiler以外の語彙プロファイラーも使ってみよう
今回ご紹介したVocabProfiler以外にも、語彙プロファイラーは多くあります。例えば、関西大学の水本篤教授が開発したNew Word Level Checker (https://nwlc.pythonanywhere.com) は、(1) New JACET 8000、(2) SVL 12000、(3) The New General Service List (NGSL)、(4) CEFR-J Wordlistという4つの語彙リストに基づいて、英単語の語彙レベルを調べることが出来ます。
New JACET 8000では、母語話者の使用頻度だけでなく、日本国内で使用されている英語教科書や入試問題などにおける出現頻度に基づき、語彙レベルを補正しています。そのため、日本における英語学習者にとっての難易度を推定したい際には、母語話者の使用頻度のみを元にした語彙リストよりも、New JACET 8000の方が適している場合もあります。
母語話者の使用頻度を知りたい場合はVocabProfilerでBNC-COCA等のリストを使い、日本における英語学習者にとっての難易度を推定したい際にはNew Word Level CheckerのNew JACET 8000を使うなど、目的に応じて使い分けると良いでしょう。
ある英文テキストの難易度を調べたり、テキスト中の重要な単語を特定する上では、語彙プロファイラーは非常に有益です。本記事の内容を参考に、語彙プロファイラーで様々なテキストを分析されてみてはいかがでしょうか?
ちなみに本記事でご紹介したVocabProfilerは、Compleat Lexical Tutor (https://www.lextutor.ca/) というwebサイトの機能の1つです。Compleat Lexical Tutorは機能が豊富で非常に素晴らしいwebサイトなのですが、多機能であるゆえに使用方法が若干わかりにくく、さらに90年代を彷彿させるデザインであるため(ずっと見ていると目がチカチカします)、とっつきにくい印象があります。本記事をきっかけに、英語学習者や英語教師にとって、Compleat Lexical Tutorがより身近なツールとなることを願っております。
なお、VocabProfilerについては、拙著『英単語学習の科学』(研究社)の2章でもご紹介していますので、そちらも合わせてご覧ください。
文責:
中田達也(立教大学異文化コミュニケーション学部准教授)
江口政貴(オレゴン大学言語学部博士課程在籍)
柳沢明文(ウェスタンオンタリオ大学教育学部博士課程在籍)
参考文献
Nation, I. S. P. (2006). How large a vocabulary is needed for reading and listening? Canadian Modern Language Review, 63, 59–82.
Nation, I. S. P. (2013). Learning vocabulary in another language (2nd ed.). Cambridge, UK: Cambridge University Press.

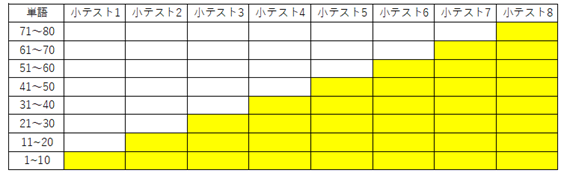 図2. 累積グループのイメージ。小テスト1では「単語1~10」、小テスト2では「単語1~20」、小テスト3では「単語1~30」が出題範囲。回数を重ねるにつれて、出題範囲が累積的に増えていく。
図2. 累積グループのイメージ。小テスト1では「単語1~10」、小テスト2では「単語1~20」、小テスト3では「単語1~30」が出題範囲。回数を重ねるにつれて、出題範囲が累積的に増えていく。